The web data layer
for finance.
Describe what you need, Kadoa builds the dataset
- Describe the web dataset you need
- Our agents build, monitor, and repair the production-ready code for you
- Extract data from websites, PDFs, images, and spreadsheets

Go from idea to dataset in minutes.
For Analysts
Build datasets in the UI or via MCP in a fully self-serve way. Describe what you need in plain language and get a structured dataset in minutes. No code required.
For Engineers
Write and run ETL code natively in Kadoa. Migrate existing pipelines in and let Kadoa handle scaling, monitoring, and self-healing.
Cloud-Native Delivery
Push data directly into S3, Snowflake, BigQuery, or any data warehouse. No glue code to maintain.
Monitor Websites in Real-Time
Get real-time updates of market-moving data changes via Slack, email, or webhooks.
Bear the bottleneck...
...or use Kadoa

If data is wrong, missing, or late, someone feels it.
We build the most reliable datasets for the most demanding customers.
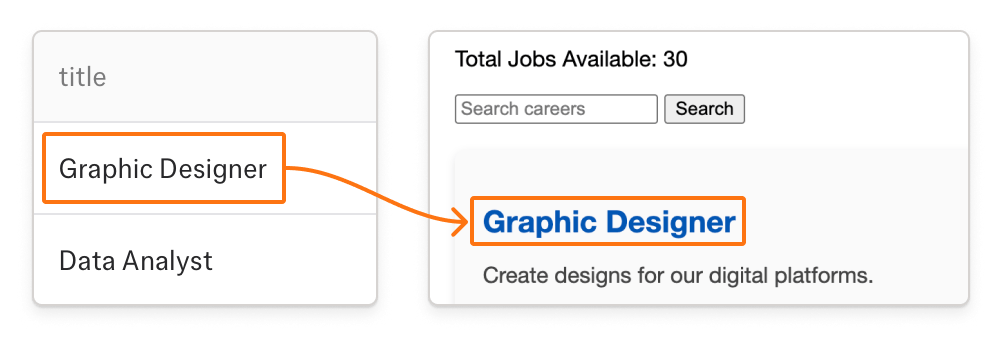
Source Grounded Outputs
Every value is source-grounded and audit-ready. Trace any data point to see the exact page, paragraph, or cell it came from. Trust but verify.

Data Quality Checks
We treat every extracted value as wrong until it passes validation. We check for completeness, plausibility, and schema adherence on every run. Add your own domain rules on top.

Self-Healing
When a workflow breaks, Kadoa detects it and fixes the code automatically. Every fix is logged so you can see what changed, when, and how it was resolved.

Transparent Error Handling & Recovery
If automated recovery fails, you get notified immediately with full context: what broke, what was tried, and what needs human review.
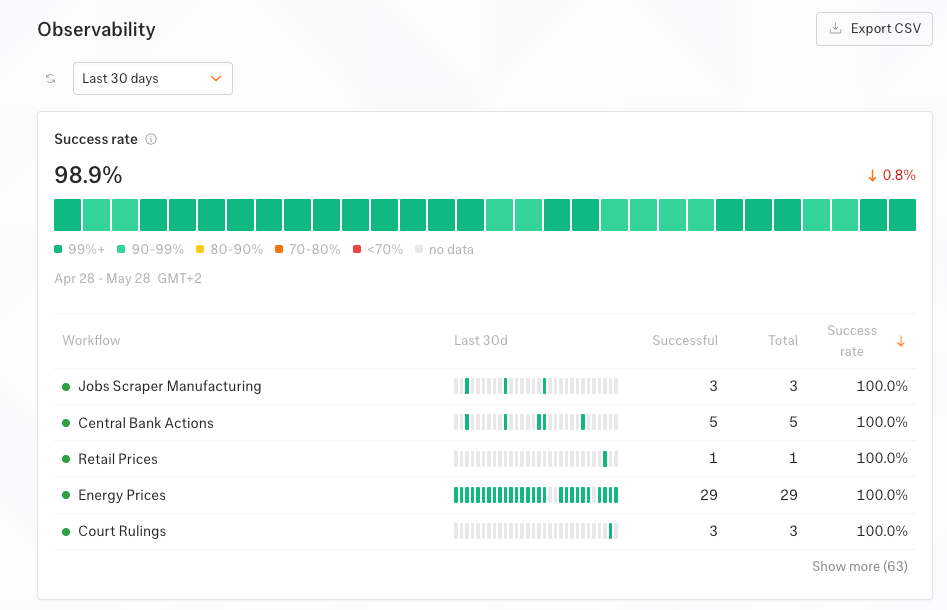
Observability
Track success rate, throughput, and incidents for every workflow in one dashboard, or stream metrics into your own monitoring stack.
Battle-Tested Tools
At scale, you need battle-tested systems for proxies, timeouts, retries, and more. We embed deep web scraping and finance domain knowledge into our subagents and skills.
AI writes deterministic code.
The code produces verifiable data.
Our agents generate and maintain deterministic code and do not produce black-box LLM outputs.
You stay in full control of your mission-critical pipelines.
Generates and maintains pipeline code.
*******

Enterprise-Ready Security
- SOC 2 certified
- Built-in platform security and privacy
- Encryption at rest and in transit
- Regular third-party penetration testing

Access Control & Auditing
- SSO/SAML with automated user provisioning (SCIM)
- Granular, customizable user roles
- Strict data isolation with multi-tenant architecture
- Comprehensive compliance and audit logs
Data Under Your Control
- On-premise or private cloud deployment options
- Data is never shared between customers
- Your data is never used for AI training
- Your workflows, sources, and schemas are strictly proprietary and confidential
Automated Compliance Rules
- Configurable compliance rules & restrictions
- Compliance officer approval before data collection
- Sensitive data detection
- Automated check of robots.txt
From Our Blog
View all posts
How Hedge Funds Source Web Data in 2026
How funds handle web scraping in 2026, and when it makes sense to build in-house versus buy from a vendor.

Introducing Kadoa Assistant, powered by our Web Scraping OS
Announcing a fundamentally better way to extract web data

The AI Data Stack for Investment Research
How investment firms transform their data stacks to make best use of AI.
Better research starts with better data.
