
What is Web Scraping? Enterprise Use Cases for 2026
 Tavis Lochhead,Co-Founder of Kadoa
Tavis Lochhead,Co-Founder of KadoaMost enterprises that need web scraping have already tried it. The proof of concept worked. Then it broke, got expensive, and landed on an engineer's plate permanently. This guide is about what comes after that: how to run web scraping at enterprise scale in 2026, where AI actually helps (and where it doesn't), how to stop losing engineering hours to maintenance, and what separates platforms worth evaluating from ones that will create the same problems you already have.
Introduction: web scraping has grown up
Something shifted in the last few years. Web scraping stopped being the thing your engineering team hacked together over a weekend. It became a line item your CFO notices.
The web scraping market hit $1.03 billion in 2025 and is projected to reach $2 billion by 2030 (Mordor Intelligence). The shift is driven by enterprise demand for ground-truth data: proprietary knowledge bases, generative model training, and real-time competitive intelligence that's difficult to source any other way. This isn't hobbyist growth; it's enterprise infrastructure spend.
But the hidden cost isn't the infrastructure bill. It's the maintenance tax. Enterprise data teams routinely report that maintenance, not extraction, dominates their engineering time. Every site redesign, every anti-bot update, every changed selector pulls your highest-paid engineers away from the work that actually moves the business forward.
The companies investing despite that cost aren't scraping because they can. They're scraping because their competitors' pricing strategies, their supply chain signals, their risk indicators: most of that doesn't come through an API.
What changed? The questions did. Enterprises used to ask "can we scrape this?" Now they ask: Can it scale across dozens of markets? Will it survive when the target site redesigns next month? Can we stop losing engineering hours to maintenance?
The market is stratifying: commodity providers offering cheap, fragile proxies at one end, enterprise-grade platforms investing in self-healing infrastructure, compliance, and identity management at the other, with specialized challengers filling niches in between.
For the organizations that take it seriously, web scraping now sits alongside APIs, internal databases, and SaaS feeds as a first-class data input.
This guide is built for the people making those decisions.
What web scraping means in an enterprise context
A single engineer can get a proof of concept running in minutes. Most teams we talk to have gotten that far. The complexity comes later: everything that happens when you try to do it reliably, across hundreds of sources, at a cadence your business depends on.
What makes web scraping an enterprise problem isn't the technology. It's the requirements. When a retail analytics team needs to track 50,000 SKUs across 14 regional marketplaces, refreshed every 6 hours, with zero tolerance for missing data, the challenge is in the requirements, not the code. When finance needs alternative data from job postings and shipping trackers to inform investment models, they need audit trails and data lineage, not a folder of JSON files.
Modern websites complicate this at every layer, and the gap between "scraping a page" and "running a reliable data pipeline" widens with every anti-bot deployment.
To understand the operational debt this creates, consider NielsenIQ's digital shelf analytics operation: over 10,000 precisely geolocated spiders processing 10 billion products per day. This infrastructure requires a dedicated team of 50 web scraping specialists, with each new spider taking 6 to 8 days to build (Fred de Villamil, 2025). And that's with a dedicated scraping team and virtually unlimited engineering budget. For most enterprises, that level of resourcing isn't an option.
The numbers confirm it. According to Apify and The Web Scraping Club's 2026 State of Web Scraping report, over 60% of scraping professionals reported increased infrastructure costs year-over-year, with adaptive defenses cited as a growing obstacle for practitioners, forcing teams to spend engineering time on evasion rather than data quality.
Enterprise scraping means building systems that handle this scale, satisfy compliance, and justify their cost. The question stopped being "can we get this data" a while ago. Now it's "can we get this data reliably, defensibly, and affordably".
Web scraping vs. APIs vs. data vendors
If web scraping sounds like a lot of work, it's worth asking: why not just use an API?
Because most of the data you actually want doesn't come through one. APIs are curated. A platform decides what to expose, how often you can access it, and what it costs. Reddit's API went from free to priced in a way that broke most third-party applications. X's API became cost-prohibitive for research use cases. Google Search's official API limits what it returns.
But those are platforms that at least offer programmatic access. Your competitors don't offer an API to monitor their pricing strategy. Suppliers rarely offer an API to track their stockouts. The most valuable external competitive data is almost always locked in the presentation layer.
Market intelligence firms like NielsenIQ, Similarweb, or specialized alt-data providers aggregate and clean data for you. But vendor data is, by definition, available to your competitors too. It's commoditized intelligence, often days or weeks behind the source, delivered in a schema someone else designed. They decide which attributes matter. You accept it. If everyone has the same dataset in the same shape, the edge shifts to analysis and speed of action, not the data itself.
Web scraping gives you direct access to the source, on your schedule, with the schema you define. Yes, it's operationally complex. But that's also why the enterprises that do it well build data advantages their competitors can't easily replicate.
Data coverage | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Freshness | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Schema control | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Competitive edge | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Maintenance | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Operational cost | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Main risk | Web scraping | APIs | Data vendors | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Enterprise web scraping use cases
eCommerce and social media dominate as the most targeted categories, with product pricing and social content consistently topping industry surveys. Those are the obvious ones. Here's where it gets more interesting.
Competitive intelligence
Product teams track competitors' feature launches, messaging shifts, and pricing moves. Strategy teams monitor job postings to infer expansion plans. Marketing watches ad copy and positioning changes via real-time monitoring. The goal is to know what competitors are doing before it becomes obvious to everyone else.
Dynamic pricing and catalog monitoring
Retailers scrape competitor pricing across thousands of SKUs, often multiple times per day. A hospitality company might track room rates across 50 booking platforms. An electronics retailer running retail price intelligence across hundreds of thousands of products for price-match guarantees isn't doing that manually; they're running scrapers that feed directly into repricing engines.
Risk, compliance, and brand protection
Legal teams track regulatory disclosures and policy changes across government sites. Brand teams monitor for unauthorized resellers, counterfeit listings, and trademark violations on marketplaces. Franchise and retail operations scrape location data to verify store hours, addresses, and regional compliance. It's defensive data collection: knowing what's changed before it becomes a problem.
Alternative data for finance
Hedge funds and asset managers have turned web scraping into an industry unto itself. Public job postings signal company health. Import records and logistics tracker pages indicate supply chain status. Company filings and regulatory disclosures across jurisdictions reveal risk signals before they hit mainstream coverage. Geospatial data from store locators and location-based sources inform site-selection and coverage analysis. The value isn't in one-time extracts; it's in consistent, longitudinal datasets that power alternative data strategies.
AI and machine learning pipelines
Training data doesn't appear from nowhere. Companies building vertical AI products (customer sentiment analysis, market research tools, search applications) need curated web data. More enterprises now use web scraping to feed AI and ML systems. Despite industry attention shifting toward RAG and agents, Cloudflare Radar data shows that training-related crawling accounted for the overwhelming majority of AI web traffic in 2025, outpacing search-related crawling at peak.
Web context for AI agents
Not all AI systems train on web data, but many need it at runtime. RAG-powered products that answer questions about markets, competitors, or regulations pull from web sources alongside internal documents. AI agents that research companies, compare suppliers, or monitor news depend on fresh, structured web data as input. As agent adoption grows, so does demand for the scraping infrastructure that feeds them.
The common thread: they're all pipelines where bad data or missing data costs real money.
Why traditional scraping fails at enterprise scale
Anti-bot systems are gaining ground.
According to the 2026 State of Web Scraping report, Cloudflare is the single most commonly encountered anti-bot system. Cloudflare, Akamai, DataDome, and similar services now deploy TLS fingerprinting, behavioral analysis, and CAPTCHA challenges that break traditional scrapers within days or weeks.
This is happening against a bigger shift: automated agents now account for over half of all internet traffic (Imperva, 2025). One major bot management vendor deployed more than 25 version updates in 10 months, often releasing changes multiple times per week. As one industry report put it: "Two days of unblocking efforts used to give two weeks of access. Now it's the other way around".
At a 2025 industry conference in Dublin, Antoine Vastel, Head of Research at Castle, a prominent anti-bot firm, revealed that proxies have become a "weak signal" in bot detection. Simply buying more proxies won't save a failing scraping operation. Detection has moved well beyond IP-level signals.
Even platforms that were challenging but manageable are hardening fast. Google deployed SearchGuard in January 2025, forcing widespread retooling across the scraping industry. In September, Google deprecated the unofficial num=100 parameter that had allowed retrieving up to 100 results per request, forcing scrapers to make 10x more requests for the same coverage and breaking many SEO tracking tools. SerpApi's CEO reported at a 2025 data extraction conference that despite spending 10x the resources, Google is now twice as slow to scrape. That's not a gradual increase. It's a step change.
The result: scraping costs that once grew linearly now escalate in steps, and every new anti-bot deployment can invalidate months of investment overnight.
Maintenance never stops.
Sites redesign, DOM structures change, and pagination logic shifts without warning. A scraper that worked perfectly last month throws errors today. One enterprise team tracking 14 marketplaces reported 9 site structure changes in a single quarter. The breakage is constant, and it's rarely predictable.
The hardest failures are the silent ones.
Bad selectors, timing issues, and geo-specific rendering don't always throw errors. Sometimes they just return incomplete data, or worse, wrong data. If you don't have validation layers and monitoring in place, you may not realize your pricing feed has been corrupted until someone makes a business decision based on it. Your scraping infrastructure needs precise definitions of what good data looks like and automated checks that flag when something doesn't match.
This is why "we'll just write some scrapers" turns into a multi-person engineering commitment within months.
The role of AI in enterprise web scraping
AI-powered scraping has dominated industry headlines over the past year. The adoption data is more mixed than the hype suggests.
Extraction is the easy part. With or without LLMs, pulling data off a page is a solved problem. The hard parts are everything else: maintenance when sites change, scaling to thousands of sources, and knowing whether the data is actually right. That's where AI is making a difference in 2026.
According to the 2026 State of Web Scraping report, only 46% of professionals surveyed currently use AI in their scraping workflows. The majority still rely on traditional approaches. Among those who do use AI, roughly 65% apply it primarily for code generation (asking ChatGPT or Claude to write scrapers) more than for extraction itself. The pattern that's emerging: asking an LLM to read the page tends to be slow and error-prone at scale; asking an LLM to write the script is proving far more effective.
That's changing. According to the same survey, 66% of non-adopters say they plan to try AI tools. And virtually all current AI users plan to increase their usage. Adoption isn't universal yet, but the trajectory is obvious.
AI-assisted coding is now widespread across the industry, and that applies to scraper code too. Veteran practitioner Pierluigi Vinciguerra shared at a 2025 web scraping summit that AI wrote over 90% of his code last year. But generating the code was never the hard part. AI-generated code still needs enterprise-grade infrastructure underneath it.
What AI does well
The biggest win is self-healing. Faster prototyping and simplified parsing help, but self-healing is what changes the economics. The mechanism behind self-healing is multimodal: the best systems use vision models to view the rendered page as a human would, locating where data sits by its visual context rather than its HTML structure. When a site moves a price field from a sidebar to the center column, a vision-based system recognizes the field by what it looks like, not where it sits in the DOM, and regenerates the extraction code accordingly.
This is what makes self-healing work in production, not just in demos. McGill University researchers (2025) tested AI extraction methods across 3,000 pages and found 98.4% accuracy even when page structures changed, with vision-based extraction costing fractions of a cent per page. Production systems add plausibility checks and completeness tracking on top, validating data quality before it reaches downstream systems.
What AI struggles with
The failure mode is specific: direct LLM extraction. Some tools pass raw HTML to a language model and ask it to return structured data. This approach is prone to hallucinations and latency. Non-deterministic outputs create problems for production pipelines. One enterprise ran a 3-month pilot comparing a traditional scraping platform against a direct LLM extraction tool for pricing data. The result: the LLM sometimes reported prices 20% off the actual value because it couldn't reliably distinguish between prices with VAT and prices without VAT. If you're using scraped pricing data to make decisions, 20% is not a rounding error.
Here's the difference that matters in practice: an LLM reading a page can hallucinate. An LLM writing a script produces deterministic code, meaning outputs are consistent and auditable. The code can still be wrong (a bad selector will quietly return the wrong field), but the failure mode is generally easier to catch and debug than plausible-looking hallucinated data.
Two approaches to AI-powered web scraping
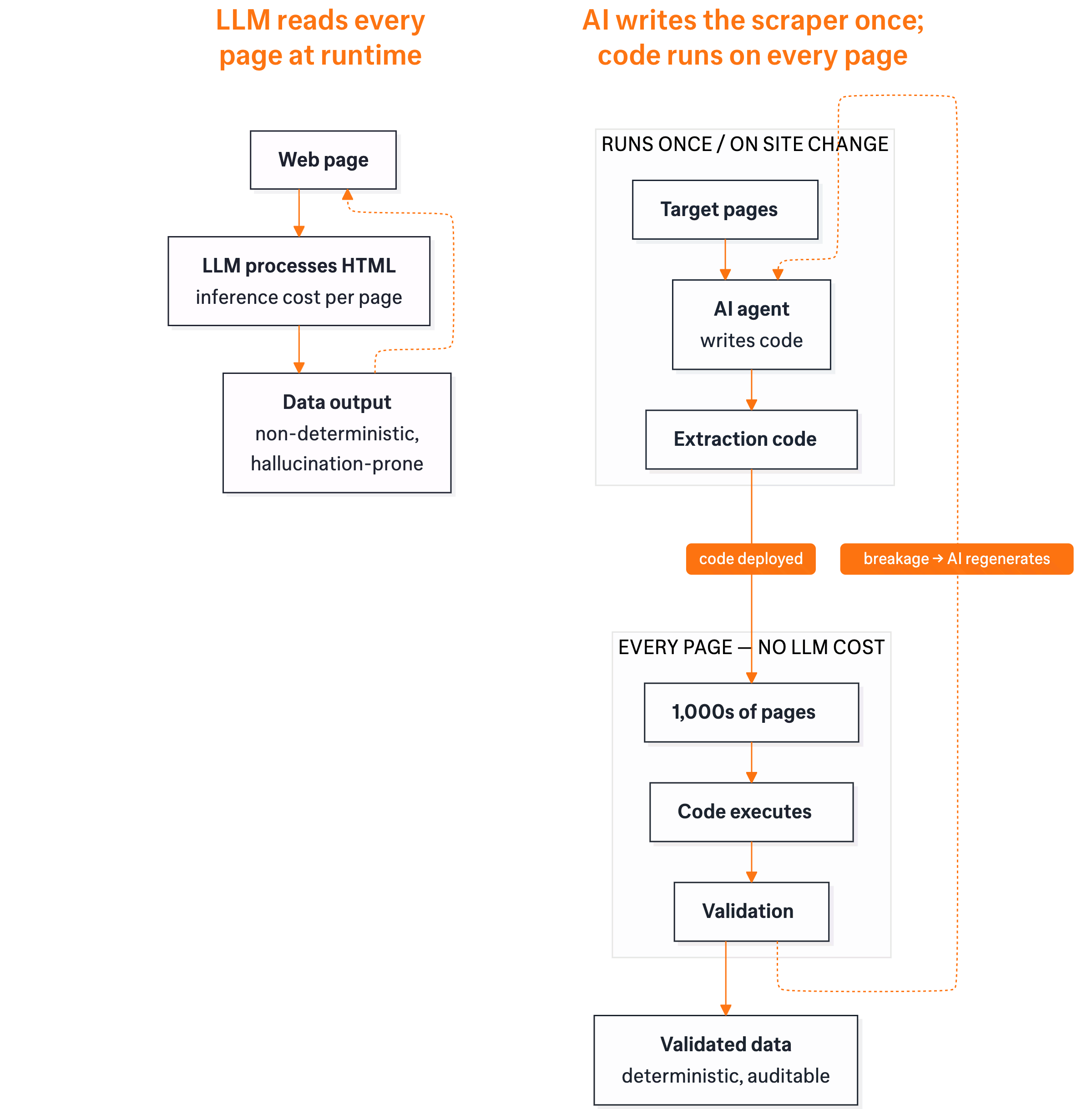
The winning architecture – AI adaptability with deterministic extraction.
Many scraping tools can scale. The harder problem is maintaining reliability and accuracy at scale: returning the right data, consistently, across hundreds of sources, even as those sources change. That's what enterprise buyers should actually be evaluating.
The reason: AI handles the variability (anti-bot challenges, site changes) while deterministic extraction ensures data accuracy. AI agents generate and continuously maintain real scraping code, not black-box LLM outputs, so every workflow runs deterministically with repeatable, verifiable results.
There's a cost angle too. Direct LLM extraction charges inference costs per page. At an enterprise scale, that's unsustainable. Kadoa's approach is different: AI agents generate the selectors and extraction code as part of an agentic ETL pipeline, so the actual scraping runs at traditional cost-per-page economics. You get AI adaptability without AI extraction costs. This is why well-designed platforms use agents for writing and maintaining scripts rather than deploying an agent for every extraction call.
AI handles variability and cuts maintenance. It doesn't replace data architecture, validation, or compliance. The best platforms use both, and they're transparent about where each approach works.
How to operationalize web scraping
Most organizations understand why web scraping matters. Where they get stuck is turning it into a reliable data pipeline. Here's what we've seen work.
Step 1 – Define your data requirements and success criteria.
Defining requirements is where the most expensive mistakes happen. Before writing a single line of code or evaluating a single vendor, get specific about what you actually need. What data? From which sources? At what refresh frequency? With what accuracy tolerance? Who consumes the output, and in what format?
The difference between "we need competitor pricing data" and "we need daily price and availability data for 8,000 SKUs across 12 competitor sites, validated against historical baselines, delivered as structured JSON to our Snowflake instance" is the difference between a side project and a production pipeline. The specificity saves you months later.
Step 2 – Assess the difficulty of your target sources.
Not all websites are equally hard to scrape. Static HTML pages with clean structure are trivial. JavaScript-heavy single-page applications require headless browser rendering. Sites behind Cloudflare or DataDome may need residential proxies, CAPTCHA solving, and browser fingerprint management. What we hear consistently from practitioners: individual sources may seem straightforward, but at enterprise scale the cumulative maintenance burden across dozens or hundreds of targets makes even "easy" sources expensive to manage in-house. Sites with serious anti-bot protection compound the problem further.
It's worth mapping your target sources against this spectrum before committing to an approach.
Step 3 – Make the build vs. buy decision.
Most organizations start with in-house development. According to industry survey data, 47% of professionals surveyed rely entirely on custom code, typically in Python using frameworks like Scrapy, Playwright, or Selenium. That works until maintenance burden exceeds capacity, scale requirements outpace infrastructure, or compliance requirements demand capabilities the in-house system was never designed for.
Building in-house gives you control and customization. But it also means owning proxy management, anti-bot bypass, infrastructure scaling, monitoring, and ongoing maintenance. At enterprise scale, teams routinely report spending 30–40% of their data engineering hours just keeping scrapers running. Not improving them. Just preventing breakage. As one industry analysis put it, the cost of orchestrating the components has become higher than the cost of the components themselves.
Lower-cost proxy providers often deliver disappointing success rates, which means your most expensive engineers spend their days debugging IP bans and rotating credentials instead of building products. When you calculate the fully loaded cost (engineering hours, infrastructure, proxy spend, monitoring, and the opportunity cost of what those engineers aren't building), an in-house scraping operation at enterprise scale frequently costs more than a dedicated platform. The real calculus isn't build cost. It's what your engineering team isn't building while they're maintaining scrapers.
The hybrid approach (using external platforms for extraction while maintaining internal control over data processing and storage) has grown to 42% of professionals surveyed. Knowing where that breakpoint falls for your specific targets is the key decision, and comparing the current generation of AI scraping platforms is a practical starting point. If you're scraping a handful of stable, well-structured sources and your engineering team has capacity, in-house development may be the right call. Where platforms add value is when the number of sources, the rate of change, or the compliance requirements exceed what a small team can maintain.
The numbers back this up. The data team at one leading hedge fund was overwhelmed maintaining hundreds of scrapers; switching to Kadoa freed 120 engineering hours per week and cut costs 40% versus their in-house operation. Separately, a market maker that was missing key market events due to slow, high-maintenance scrapers increased monitoring coverage 5x with minimal ongoing maintenance after migrating to Kadoa. In both cases, the teams stopped maintaining scrapers and started using the data.
Step 4 – Establish governance before you scale.
Compliance isn't something to bolt on after your scraping infrastructure is running. Define your robots.txt policy, your PII handling rules, your data retention schedule, and your audit logging requirements at the outset. The governance layer should be designed in, not retrofitted.
Kadoa, for example, is SOC 2 certified and provides automated compliance controls that enforce rules programmatically: robots.txt enforcement with the option to strictly decline CAPTCHA challenges (so your scraping is legally defensible if challenged), PII detection that can be configured to redact or block sensitive data, a dedicated compliance officer role for approval workflows, and a commitment that customer data is never used for AI model training. For regulated industries, on-premise and private cloud deployment options keep data within your own infrastructure.
Step 5 – Pilot, validate, then scale.
Run a controlled pilot on 5-10 representative sources before scaling to hundreds. Validate output quality against manually verified baselines. And critically, test failure recovery: what happens when a site redesigns? When a CAPTCHA appears? When data comes back empty? What matters isn't whether the system works on day 1, but whether it's still working well on day 30.
What to look for in enterprise platforms
Self-healing capabilities that adapt to site changes without manual intervention, plus transparent error handling for when self-healing can't resolve the issue (site goes offline, URL changes entirely), so your team gets notified immediately and the vendor's operations team steps in rather than leaving you to discover stale data downstream. Transparency into how data was extracted: the underlying extraction logic should be auditable, not locked inside a vendor's black box.
Source grounding and confidence scoring that trace every data point back to where it came from and flag uncertain values for review, giving compliance teams a verifiable chain of provenance. Integration with your existing data stack (S3, Snowflake, webhooks, wherever your pipelines live). And predictable pricing you can defend in a budget review.
What's ahead for enterprise web scraping
If you're building a web scraping capability today, it helps to know where the ground is shifting. 5 trends are worth watching closely.
Web data infrastructure becomes the critical AI layer. The search and data layer on top of foundation models may prove more valuable than the training data itself. More and more LLM-powered applications depend on real-time retrieval. As companies build industry-specific AI agents for legal, healthcare, finance, and hospitality verticals, they need specialized data not easily accessible on the public web. The enterprises that control reliable, compliant access to that data will have advantages that model improvements alone won't easily replicate.
The web itself is fragmenting into different access regimes. The open web, one set of rules and one access strategy, is giving way to 3 distinct zones.
The "hostile web", where sites deploy aggressive honeypots, AI-targeted challenges, and escalating fingerprinting to block all automated access. The "negotiated web", where publishers adopt licensing, pay-per-crawl, and emerging machine-readable permission standards like llms.txt. And the "invited web", where sites actively expose agent-friendly interfaces, initially for commerce (Stripe's Agentic Commerce Protocol, the Universal Commerce Protocol, Visa's Trusted Agent Protocol), but the pattern extends to any structured data exchange. As more sites build machine-readable access layers for AI agents, the same infrastructure that powers agentic checkout will reshape how enterprises access product, pricing, and inventory data. Platforms that support AI-native navigation will have an advantage in this zone.
Enterprise scraping strategies that assume a single approach won't hold up. You'll need capabilities across all 3.
The cost curve keeps climbing. Anti-bot systems are getting more sophisticated, not less. Proxy expenses, CAPTCHA solving, and infrastructure costs will continue rising. Organizations that treat scraping as a side project will find it unsustainable; those that treat it as infrastructure will invest accordingly.
AI becomes standard, but not sufficient. AI-assisted scraping will move from competitive advantage to baseline capability within the next few years. But the concerns practitioners raise (hallucinations, non-determinism, scalability) won't disappear just because the models improve. The approach that holds up will combine AI adaptability with deterministic validation layers.
Market consolidation is accelerating. Hundreds of millions in venture capital flowed into AI-native web scraping and browser infrastructure startups in 2024–2025 alone. That influx has created a new generation of competitors forcing incumbents to adapt. But dozens of overlapping tools with unsustainable economics won't persist. The companies best positioned to survive will be those with real enterprise infrastructure. Expect fewer, stronger players serving the enterprise segment by 2028.
Conclusion
The case for enterprise web scraping is clear. The question now is execution.
If your organization depends on external data (and most enterprises increasingly do), the harder question is how to access it reliably, at scale, and in a way that holds up over time. That means moving past ad-hoc tooling and evaluating scraping as you would any other critical data pipeline: with attention to reliability, maintainability, total cost of ownership, and risk.
The companies getting this right are building something their competitors can't easily catch up to. If you want to see how the architecture works under the hood, that's a good place to start.
Ready to operationalize web data?
We built Kadoa for the exact challenges this guide describes. AI agents that write and continuously maintain scraping scripts so they self-heal when sites change. Deterministic extraction you can audit. Enterprise teams that stop maintaining pipelines and start using the data. If you're evaluating platforms, here's where to start:
Explore Kadoa | Book a demo | Start your free trial | Read the docs
Frequently asked questions
Is web scraping legal?
Web scraping of publicly available data is generally legal, but the boundaries depend on jurisdiction, the type of data, and how you access it. The safest approach: respect robots.txt, avoid personal data unless you have a lawful basis, maintain audit trails, and treat compliance as a design requirement rather than an afterthought.
What is the difference between web scraping and web crawling?
Web crawling discovers and indexes pages (following links, mapping site structure). Web scraping extracts specific data from those pages. Enterprise pipelines combine both: a crawler discovers URLs, a scraper extracts structured data from each one. Most modern platforms handle both as a single workflow.
How does AI improve web scraping?
AI's biggest operational gain is self-healing: when a website redesigns its layout, AI agents detect the change and regenerate extraction logic automatically, cutting the maintenance burden that breaks traditional scrapers. AI-powered code generation also produces working scrapers in minutes instead of days.
It comes down to architecture. The best AI scraping platforms use AI to generate deterministic code rather than relying on LLMs to extract data at runtime, which avoids hallucination and consistency problems. The agents write and continuously maintain the scripts, but the scripts themselves execute deterministically. This is more reliable than deploying an agent for every run. AI also improves data quality through automated validation and anomaly detection.
What should I look for in an enterprise web scraping platform?
Ask about failure modes. How does the platform handle a site redesign? What happens when anti-bot protections change? Can you see exactly how data was extracted, or is it a black box? Does it log what was collected, when, and from where? The right platform should be able to answer these confidently.
Red flags include: requiring manual intervention when sites change, opaque extraction with no audit trail, and pricing models that scale linearly with page volume (which becomes unsustainable at enterprise scale). The capabilities are covered in detail in the operationalize section above.
See how Kadoa's architecture addresses each of these.
How much does enterprise web scraping cost?
In-house scraping at enterprise scale often exceeds $10,000–$20,000 per month in fully loaded costs (proxy spend, infrastructure, engineering time, monitoring), and that's before you account for delayed or missed data when scrapers break. Managed platforms consolidate these costs into predictable pricing.
Don't compare platform cost against proxy cost. Compare total cost of ownership. As discussed in the build-vs-buy section above, the maintenance burden alone consumes a significant share of data engineering capacity. Managed platforms like Kadoa take that burden off your team with predictable pricing. Self-healing resolves most issues automatically, and when it can't, Kadoa's team steps in.
How long does it take to get a web scraping pipeline into production?
A single scraper for one well-structured source can be prototyped in hours. Getting to production, with validation, monitoring, error handling, and integration into your data stack, typically takes weeks for in-house teams, longer if anti-bot defenses are involved.
Managed platforms compress that timeline. With Kadoa, most enterprise teams go from first extraction to production pipeline in days rather than weeks, because the platform handles infrastructure, anti-bot bypass, and self-healing out of the box.

Related Articles

How AI Is Changing Web Scraping in 2026
Explore how AI is changing web scraping in 2026. From automation and data quality to compliance to scalability and real-world use cases.

The Top AI Web Scrapers of 2026: An Honest Review
In 2026, the best AI scrapers don't just write scripts for you; they fix them when they break. Read on for an honest assessment of the best AI web scrapers in 2026, including what they can and cannot do.

The AI Data Stack for Investment Research
How investment firms transform their data stacks to make best use of AI.